GAN,即生成对抗网络,是一种无监督的生成模型。主要包含两个模块:生成器(Generative Model)和判别器(Discriminative Model)。生成模型和判别模型之间互相博弈、学习产生相当好的输出。
The most important one, in my opinion, is adversarial training (also called GAN for Generative Adversarial Networks). This is an idea that was originally proposed by Ian Goodfellow when he was a student with Yoshua Bengio at the University of Montreal (he since moved to Google Brain and recently to OpenAI).
Yann LeCun 认为 GAN 很可能会给深度学习模型带来新的重大突破,事实证明了,在 2014 年GAN被提出的一两年之后,基于生成对抗网络的研究飞速增长,这一点也体现在了机器学习模式识别领域的顶会接收论文中GAN研究的占比中。
在 github 上的一个收集了目前绝大多数 GAN 的仓库:GAN ZOO,里面有几百种叫得出名字的GAN。
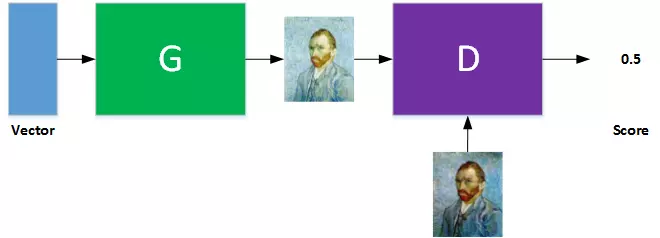
在 GAN 的模型中生成器负责生成样本,判别器则负责鉴别样本是来自生成器还是真实的样本。生成器的输入往往是随机噪声,判别器的输入则是真实的样本和生成器生成的样本以及对应的标签(标记样本是True or Fake)。
在训练过程中,使用两个损失函数,其一是生成的图像的判别loss,其二是判别器的判别loss。理想情况下,在多个迭代训练中,生成器的生成结果会越来越接近真实样本,判别器最终难以分辨真实的样本和生成的样本,此时网络训练完成。
这里基于 Py-Torch 实现的基本GAN的生成器和判别器,来自git仓库。
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
整个网络都是由全连接构成,每个全连接后面跟着批量正则化和leakyReLU。
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
从网咯的结构中可以看出,g_loss 和 fake_loss两者的输入仅仅是对应的真假标记不同,因此在训练过程中,两个loss可能存在其中一个(往往是判别器的)loss下降而判别器的loss不断上升。判别器越好,生成器梯度消失越严重,可见两者之间需要谨慎平衡 G 和 D 的训练程度。
(1)很难使一对模型(G和D同时)收敛,这也会造成以下第(2)点提到的模式崩溃。大多深度模型的训练都使用优化算法寻找损失函数比较低的值。优化算法通常是个可靠的“下山”过程。生成对抗神经网络要求双方在博弈的过程中达到势均力敌(均衡)。每个模型在更新的过程中(比如生成器)成功的“下山”,但同样的更新可能会造成博弈的另一个模型(比如判别器)“上山”。甚至有时候博弈双方虽然最终达到了均衡,但双方在不断的抵消对方的进步并没有使双方同时达到一个有用的地方。对所有模型同时梯度下降使得某些模型收敛但不是所有模型都达到收敛最优。
(2)生成器G发生模式崩溃:对于不同的输入生成相似的样本,最坏的情况仅生成一个单独的样本,判别器的学习会拒绝这些相似甚至相同的单一样本。在实际应用中,完全的模式崩溃很少,局部的模式崩溃很常见。局部模式崩溃是指生成器使不同的图片包含相同的颜色或者纹理主题,或者不同的图片包含同一只狗的不同部分。MinBatch GAN缓解了模式崩溃的问题但同时也引发了counting, perspective和全局结构等问题,这些问题通过设计更好的模型框架有可能解决。
(3)生成器梯度消失问题:当判别器非常准确时,判别器的损失很快收敛到0,从而无法提供可靠的路径使生成器的梯度继续更新,造成生成器梯度消失。GAN的训练因为一开始随机噪声分布,与真实数据分布相差距离太远,两个分布之间几乎没有任何重叠的部分,这时候判别器能够很快的学习把真实数据和生成的假数据区分开来达到判别器的最优,造成生成器的梯度无法继续更新甚至梯度消失。
原文链接: https://blog.csdn.net/weixin_43698821/article/details/85003226
除此之外GAN还存在着生成器和判别器的loss无法指示训练进程、生成样本缺乏多样性等问题。在近两天的尝试中,发现如下方法或可以为解决训练难的问题提供一些小的技巧。
Wasserstein GAN(简称WGAN)解决了如下的问题:
彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度
基本解决了collapse mode的问题,确保了生成样本的多样性
训练过程中终于有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练得越好,代表生成器产生的图像质量越高(如题图所示)
以上一切好处不需要精心设计的网络架构,最简单的多层全连接网络就可以做到
作者整整花了两篇论文,在第一篇《Towards Principled Methods for Training Generative Adversarial Networks》里面推了一堆公式定理,从理论上分析了原始GAN的问题所在,从而针对性地给出了改进要点;在这第二篇《Wassertein GAN》里面,又再从这个改进点出发推了一堆公式定理,最终给出了改进的算法实现流程,而改进后相比原始GAN的算法实现流程却只改了四点:
判别器最后一层去掉sigmoid
生成器和判别器的loss不取log
每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
