一般的分类网络,在实际的人脸识别的应用中是无法使用的。
例如手机的人脸解锁,拍一张图片来进行解锁验证,显然是不能用训练网络的方法进行。
一种方法是衡量图像之间的相似度,对于给定的图像(anchor)来识别测试的图像是否和anchor是同一个人。

形式化的表达就是找到一个度量,使得来自同一个人的照片和anchor的距离最小,来自不同的人的照片和anchor的距离最大。

2006年,lecun等人提出以下的损失函数: \(L_{contra}=(1-y_i)\frac{1}{2}(d(a, b)^2) +y_i\frac{1}{2}(max\{0, m-d(a, b)\}^2)\)
其中 $y_i$ 取值为0, 1分辨表示a,b是同一人和a,b不是同一人。m来保证loss有界。

缺点:该loss是个很强的约束,要求 $d(a,b)=0$,而实际上数据层面往往难以实现,进而导致模型崩溃。

2015年来自谷歌的facenet,提出的 triplet loss 解决约束过强的问题。

Triplet loss 将样本分为三种情况
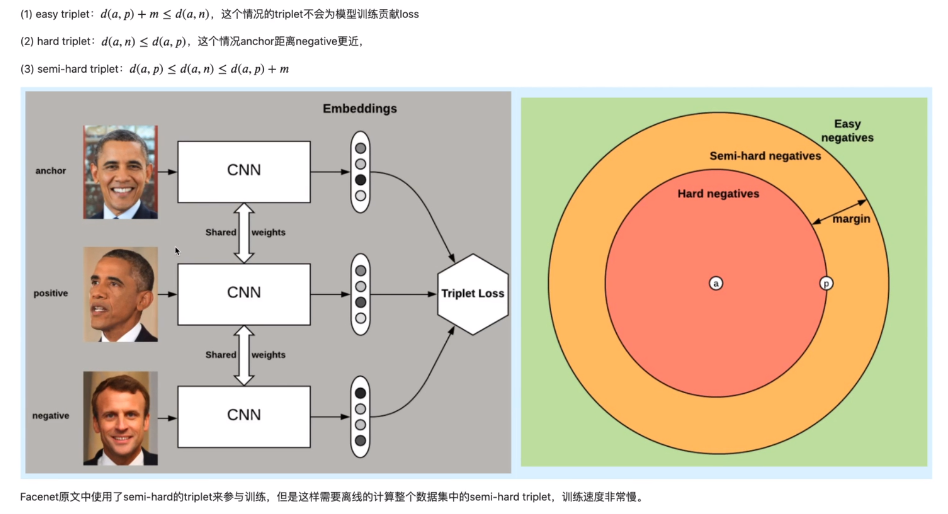
facenet在每个epoch结束都要计算一下三类样本,选择semi-hard样本进行训练,使得模型训练很慢
In defense of the Triplet loss for person re-identification提出了一个在线难样本挖掘机制,在每个mini-batch里进行
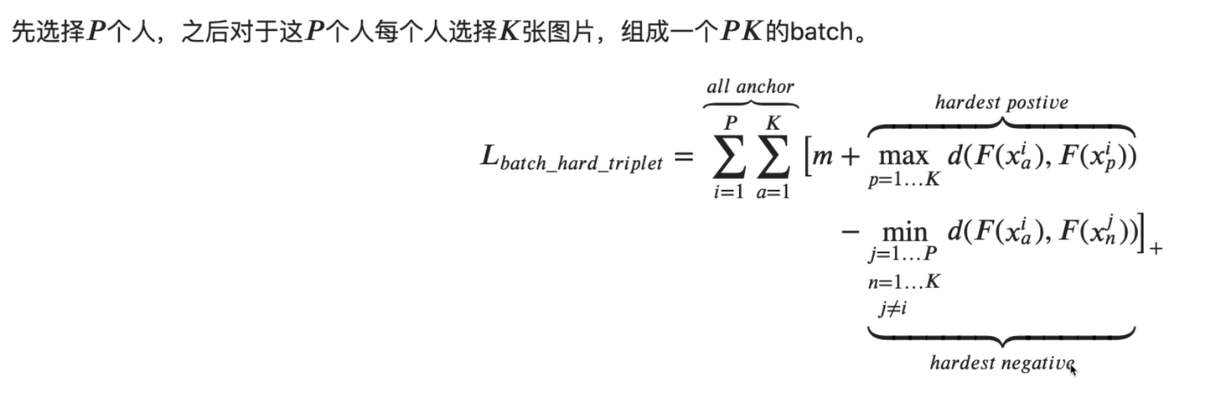
在每个mini-batch里面寻找最难的positive 和最难的 negative 来进行优化。
为什么分类不能做?
 分类目的往往只在于得到分类面,而判别性任务则得到各类可判别的结果。
分类目的往往只在于得到分类面,而判别性任务则得到各类可判别的结果。
如上所说,分类网络只是希望得到可分的特征,那么有没有办法让分类网络也能得到可判别的特征。


hinge loss向非目标类传递一个+1的梯度,如果类别很多,目标类得到-1的梯度,非目标类得到C-1的梯度,非常容易梯度爆炸。
进行修改,对应非目标类中,仅给分数最高的那一类传递+1的梯度可以解决梯度爆炸的问题。
\[L=max\{max_{i\neq y}\{z_i\}-z_y+m,0\}\]该模型存在另一个问题,每次仅传递给目标类-1的梯度和非目标类+1的梯度,模型收敛很慢。
采用一个 smooth 版本的max让每个非目标类都得到梯度。max函数的smooth版本是logSumExp函数。
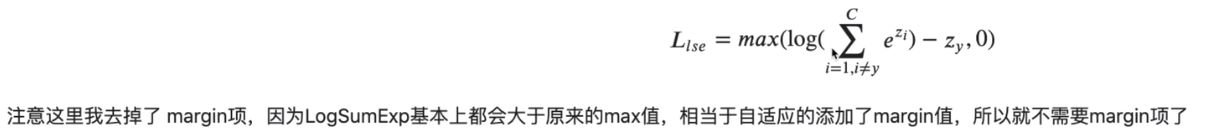
logSumExp函数的梯度是Softmax函数,因此对于非目标类中的各类,越强的样本分的梯度更大。
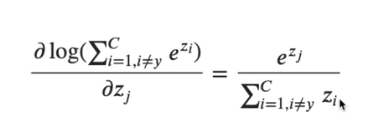

这里是视频课程地址
